PixInsights Tips: Proper use of Regularized Richardson-Lucy Deconvolution
Deconvolution. It’s a funny sounding word for what many may conceive a funny concept. It might help to understand it is the undoing of convolution, however that’s a funny word, too. As a generalized concept, convolution represents the blurring done to an image as it is resolved by an optical system and recorded by a sensor. Therefor, the purpose of deconvolution is to undo that blur, to “deblur” the image, or to “reconstruct” the image. It is important to understand the distinction in those terms, and not to confuse deconvolution with sharpening.
Sharpening is a different process, and aims to artificially enhance data to make it appear “sharper”, while deconvolution attempts to undo what has been done and recover true details. Sharpening is not a recovery process, nor is it an image reconstruction process, it is an enhancement process. However deconvolution is indeed an image reconstruction process.
Both sharpening and deconvolution can be useful tools in image processing, however each has their place in the workflow, and each affects the image in specific ways that require appropriate application at the appropriate time. Deconvolution is an early-stage process, most appropriately applied to the linear data before any other changes have been made to it. In large part this is due to the fact that deconvolution relies on the creation of a PSF, or Point Spread Function, that models the blurring caused by the optics and the atmosphere. The PSF is a critical factor in achieving proper deconvolution, and must be modeled after stars that are still linear in nature to be most effective.
Proper Deconvolution
The thing about deconvolution is it’s what we call an “ill posed” problem. Such problems violate one or more of the rules of well-posed problems, and in the case of deconvolution, it is unstable due to the fact that it is highly sensitive to error (noise) in the final image. This is particularly true with iterative deconvolution algorithms, such as the Richardson-Lucy used in PixInsight. Small errors can interfere with the process through each iteration, and can rapidly grow to become very large errors. Furthermore, the solution is highly dependent on properly estimating things we cannot necessarily know. Regularization is a means of resolving some of these issues, introducing some stability into the problem, allowing us to focus on getting accurate estimates of the PSF instead.

To Mask or to Regularize
The first question you may ask here is, why regularize? Masking is by far the most recommended technique to “protect” the deconvolution algorithm from the noise in the image. A moderate mask is usually created to expose the brighter structures and the stars to deconvolution, while blocking it from affecting faint details. While a common practice, it is far from the most ideal means to control the potential of noise in an image from affecting the deconvolution algorithm. Noise exists in every part of the signal, including the brighter parts (which when it comes to astrophotography, excluding the stars, are often marginally brighter in linear terms than the fainter parts).
Regularization, on the other hand, allows you to deduce the nature of the noise directly, and at multiple scales, thereby allowing you to product the deconvolution algorithm throughout the entire image. This includes the brighter regions…and it also includes the stars. This can help minimize error in the stars as well, which are often prone to artifacts such as ringing (both dark, and if you push the algorithm hard enough, oscillating dark and bright rings, approximating diffraction). It is an integrated aspect of the Regularized Richardson-Lucy deconvolution algorithm built into PixInsight’s Deconvolution process. It could be considered an integrated multi-scale masking technique for deconvolution, one that can be ideally tuned for the noise characteristics of each individual image.
While manual image masking may be effective, I propose that using the regularization feature of PixInsight is more ideal, and also more appropriate to not only estimating/modeling the characteristic of the noise, but managing it within the highly iterative Richardson-Lucy deconvolution algorithm. My recommendation is to use the regularization feature of the Deconvolution process for all deconvolution rather than masking. With proper regularization, masking simply becomes unnecessary, it properly protects the entire image and signal range, and is highly tunable for optimizing results.

Real or Synthetic PSF
Once you have dealt with the noise, which is the primary source of error and therefor instability in the deconvolution process, you need to accurately estimate the PSF. This is the key estimation in deconvolution, and the better this estimate is, the better the results of our deconvolution will be, the farther we will be able to push it, and the more accurately we will be able to approximate the original state of the information in the image. Poor PSF modeling will not necessarily prevent you from deconvolving, however it will force you to take more extreme measures to avoid artifacts that can be introduced during the process, and it will limit how far you can go in terms of reconstructing the original image.
My preference these days is to spend the necessary time generating an accurate PSF model, rather than fiddling with sliders to tune a synthetic PSF. In the past, I used synthetic PSFs fairly extensively, and while they can indeed be effective, they are also hit and miss. To be truly effective, a synthetic PSF must model the stars as accurately as possible, and there is no definite way to do that with a synthetic model in my experience. Getting close requires fairly extensive fiddling which can be quite time consuming. That said, sometimes a synthetic model is the only way to go, as generating a model may be difficult for a number of reasons. One particular use case for a synthetic PSF is when you have high eccentricity that a generated model may not actually be modeling correctly. PixInsight’s DynamicPSF process seems to prefer generating round PSFs, and in my experience has a tough time with highly eccentric stars.
For rounder stars, a generated PSF model is the best way, IMO, to find a best fit between the model and the average stars in your image. Generating a good PSF is actually not that hard, however it does require some knowledge of how the DynamicPSF process works and how best to use it. With proper use and proper culling of poor quality star samples, excellent PSF models can be generated that closely model the stars in your image, for most images, and this will give you the best results with the Deconvolution process. I recommend generating a proper PSF model for all of the images you wish to deconvolve, if possible, unless you can only reasonably model the stars with a synthetic PSF.
The Point Spread Function
Before we actually get into deconvolution, the first thing we need to do is model the PSF, or point spread function. The PSF is what describes the function that blurs the original image that we are trying to resolve. Note that, the PSF is a function, meaning it is not just a simple scalar value that can be represented by a single number, but something more complex. When it comes to deconvolution, a PSF attempts to find a best fit with a common geometric model, such as Gaussian, to the shape (geometry) of the stars in the image. A best fit is where the PSF that is generated by the computer most closely models the stars in the image with a minimum error. A poor fit between the PSF and the actual stars in the image will result in poor deconvolution, or quite possibly even further blurring! The smaller the error between the modeling function and the actual measurements of the star, the better the fit.
For those who are interested, fitting error is modeled as a MAD (mean absolute deviation), rather than an RMS (root mean square) in PixInsight.
Not all stars will actually conform to a Gaussian model. For those unfamiliar with what this means, think of a classic bell curve…a curve that is “peaked” in the middle, and falls off with a bell shaped outline as you move away from the middle. Some stars, often most stars, may be better approximated by a Moffat or Lorentzian model. Saturated or nearly saturated stars will generally have a Gaussian form: less peaked, flatter, more rounded. If you have very good seeing and dark skies, your unsaturated stars may even have a Lorentzian form: narrower, taller, more sharply peaked. These are star profiles, and this is an important aspect of properly modeling the PSF. Here is a chart of artificial star spots generated using the various geometric models, along with their two dimensional profiles, to help you visualized the differences between these functions…between these PSFs:
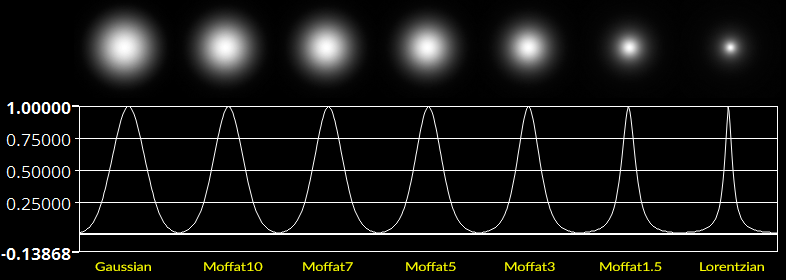
Unsaturated stars will often conform to Moffat, which is more peaked than Gaussian, but less peaked than Lorentzian. These models “fill the gap” between softer Gaussian stars and sharper Lorentzian stars. Moffat stars have an additional exponent called beta or β, that controls the shape of the model. Most unsaturated stars in an image will usually be best approximated by a Moffat model, however the model can range from nearly Lorentzian in form (Moffat1, β=1) to nearly Gaussian in form (Moffat10, β=10). Many very bright, nearly saturated stars that have entered the non-linear range of the sensor may start to fatten/flatten into Moffat10 shapes, is basically the same as Gaussian. It is preferable to reject all Gaussian and Moffat10 stars from a PSF model generated from star samples in your image. Below is another visualization of the above star models, only in three dimensions, which might help you further visualize an image in an alternative context:
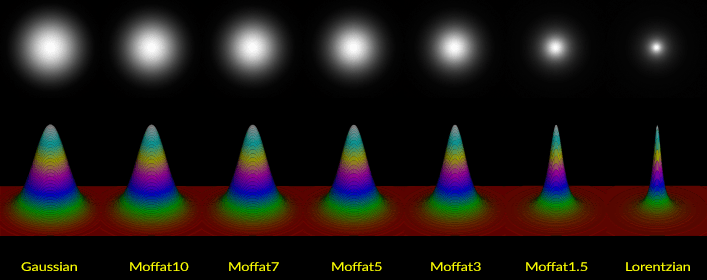
Now, one interesting little note. If all your stars are Moffat1.5 and/or Lorentzian, then deconvolution probably won’t do much for you. For an image to primarily have such stars, it would already have to be pretty sharp. Imaging on a night of phenomenal seeing with a high resolution scope and smallish pixels, with impeccable tracking, and you could very well end up with such data. Deconvolution isn’t really meant for such images. What deconvolution will attempt to do is redistribute the energy of the stars with fatter profiles from their fainter outer regions into their peaks. This has the effect of narrowing their profiles, giving them geometries more like the naturally sharper stars. The same thing happens for details as well…energy that has been dispersed is re-concentrated.
DynamicPSF
One of the most useful tools for modeling the PSFs in your image is DynamicPSF. This is a dynamic process in PixInsight that will allow you to sample actual stars in your image in order to produce an accurate PSF. For dynamic PSF modeling to be effective, it works best on images that are well sampled. You need your stars to cover ~2×2 pixels or more (and more tends to be better). Stars that are undersampled, less than 2-3x, such as with wide field images and larger pixels, are much more difficult to deconvolve, and are often best modeled using a synthetic PSF.

Bring up DynamicPSF and select a moderately sized, unsaturated star in your image. It is important that you select unsaturated stars, as saturation chops off the peak of the star, changing it’s profile. As such, ideally you want most if not all of the sampled stars in your image to have Moffat model. Remove any Moffat10 and Gaussian stars, as shown in the above screenshot. (NOTE: PI’s names for Moffat models can be a little confusing. The standard model range for beta is 1.5, 2.5, 4, 6, 8 & 10. The names for these models are Moffat15, Moffat25, Moffat4, Moffat6, Moffat8, Moffat10. Don’t confuse Moffat15 to be 15…it’s 1.5, nor Moffat25 to be 25…it/s 2.5. The largest Moffat model is Moffat10, with Moffat15 and Moffat25 being the two smallest.) You can find the actual beta in the beta column. If the beta exactly matches one of the standard range, the special name for that Moffat will be used.

To actually create a PSF model with DynamicPSF, you must choose a number of stars in your image that have good, unsaturated profiles, then generate a PSF model (which is rendered to a new image) from the best selection of those chosen. When choosing stars, in addition to avoiding saturated stars, you want to choose stars that have a profile that represents the majority of the stars in the image. This means choosing well isolated stars, so avoid double stars or stars that have close neighbors. Avoid stars with optical aberrations that only occur in part of your field, such as comatic or astigmatic stars in the corners, stars that exhibit tilt issues, etc. While it may seem appealing to try and correct these errors with deconvolution, such correction requires far more accurate modeling, as well as differential modeling based on the location within the frame, not to mention far more advanced deconvolution software (which usually only comes in the custom variety.)

Picking from the central region of the field is best, although try to make that region as large as possible without selecting defective stars. Deconvolution of this manner is designed to redistribute blurred energy and restore original sharpness as best as possible. Select up to around 40-50 stars or so, perhaps more if you find you are getting a lot of Gaussian and Moffat10 stars. To select a star, you simply need to click it in the image. If a proper star is detected there, it will be added to the list for that image in DynamicPSF.
A small indicator will be rendered around each selected star. These indicators, called PSF Coordinates, are actually quite useful, as they visually indicate the nature of the stars. In the above image, you can see three selected stars. The one near the top is round with no obvious rotation. The highlighted green one is also mostly round, but has a rotation factor (which can only be the case if the width of the star is different than the height). The one near the bottom is clearly elliptical rather than round, and would be a good candidate for removal if it does not generally represent the PSF of the whole image. (Note also that the star at the bottom may have a faint companion star within the box, which could very well be the reason the PSF model is elliptical rather than round…make sure your selected stars are isolated!) A more detailed breakdown of the PSF Coordinate is shown below:
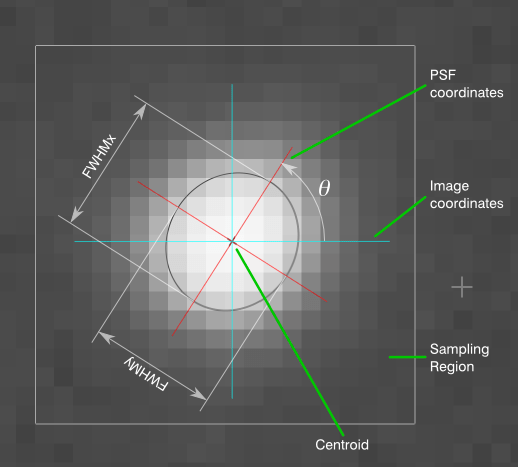
Culling the PSF Samples
Once you have chosen enough stars in the image, you will want to “cull” the list. This will eliminate outliers that don’t necessarily represent the true PSF of the image, allowing you to generate an accurate model. As mentioned above, remove any Gaussian and Moffat10 stars. Since Lorentzian represents very sharp stars, you probably want to eliminate any of those as well, and maybe also eliminate Moffat15 (1.5) stars as well. If the majority of your stars are Moffat15 or Lorentzian, then my recommendation here is don’t deconvolve! You already have sharp data. After removing the model type outliers, it’s time to remove other outliers. Click the Sort Stars button in the toolbar in the DynamicPSF window, then select MAD (Mean absolute difference) from the list of sorting criterion.
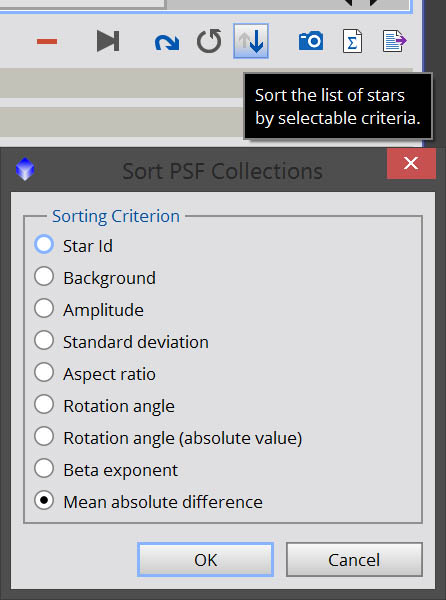
Once you have sorted, find the MAD column in the PSF list. It’s the last column. You should find that the stars with the smallest MAD are at the top of the list, while the stars with the largest MAD are at the bottom of the list. The smaller the MAD is, the better, as this represents the error between the selected modeling function (Gaussian, Moffat, Lorentzian) and the actual measurements of the star in the image. You want to keep the stars with the smallest error, and remove the stars with the largest error.
When you select the worst few stars, you should try zooming in on those stars in the image (double click the star in DynamicPSF to center it in the image). You will most likely find that stars such as the elliptical one in the example above are usually some of the worst fit stars in the image. That was indeed the case with my working image of Tulip nebula here. You can remove the worst N offenders, or you can be more selective about it, examining each poorly fit star to see what the issues likely were. It’s ok to remove a good number of stars…you do not necessarily need a lot of stars to generate a good PSF. You do, however, need well modeled stars.
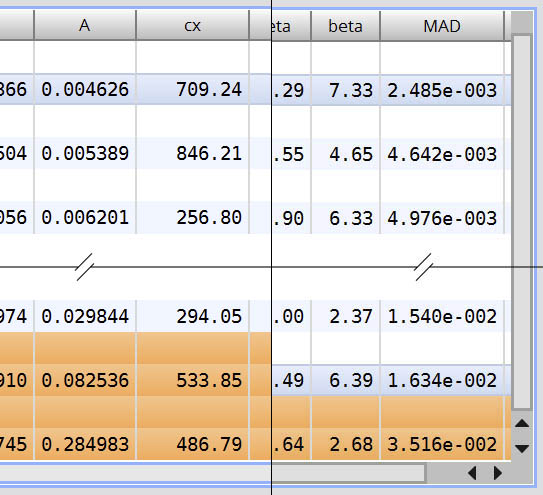
After removing the worst offenders when sorted by MAD, you can try sorting by other criteria as well, and remove the worst few offenders from each sort. I will also usually sort by Amplitude, which represents the brightest value in the selected stars (and also the “centroid” or center pixel at which the peak occurs), and remove the stars that have clearly outlying values. You may also try sorting by aspect ratio, which is the sy value divided by the sx value, and shown in the r column. These two values are the sizes (sigmas) of the fitted functions in the X and Y directions of the star (see the above PSF Coordinate image), and by design sx is always the larger while sy is the smaller, so r will always have a value of 1 or less. A perfectly round star will have an r of 1.0. Good stars from a roundness standpoint will have r values over 0.9. As the aspect ratio drops below 0.9 you may start to see increased eccentricity in the stars (elliptical shape in the PSF Coordinate). Remember that you want to select stars that have consistency, so when culling stars by aspect ratio, the goal is not to keep those that are roundest, but to eliminate those that deviate from the norm by a large amount.
After culling, you will likely have fewer than 40 stars still in the list for generating a PSF model. That is ok, as long as you culled fewer than you kept. If you culled more than you kept, then you might want to reconsider the thresholds at which you are choosing to remove stars, and the areas within the image that you selected stars. If you started out with 50 stars and removed 20 that had clearly bad traits, that is ok. If you removed 40, and kept only 10, then you should revisit your image and see if you can find a better sampling of stars. If, for some reason, you simply cannot find a consistent set of stars to generate a PSF from, then you should very seriously consider that you may have a critical optical issue with your equipment. Sensor tilt, focuser sag, improper spacing, poor focus, etc. can all lead to inconsistent stars, and these factors should be fixed before you try to deconvolve, as convolution is the very least of your problems (and note, deconvolution is NOT a magic fix for these kinds of issues!)
Generating the PSF Model
Once you have removed the outliers from your list, you want to generate the PSF model. This creates a small new image with what looks like an artificial star in it. For all intents and purposes, it is a star, generated based on the information found in your image itself. It represents a star that has been convolved (blurred) by the atmosphere and your optics at the time the image was generated. As such, it can be used to try and reverse that blurring, and do so with a fairly high degree of accuracy. The first thing you need to do is select all the remaining stars for the chosen image in DynamicPSF. They should all highlight orange. Note that you can actually sample stars from multiple images simultaneously with DynamicPSF. Make sure when you select the stars that you are selecting them only for the image you wish to generate a PSF for. I’ve found on a few occasions that I accidentally clicked on another image in the background of my PI workspace and selected stars there unawares.
Once you have selected your list of stars, you want to generate the PSF. You can do this one of two ways. You can click the blue camera icon on the toolbar in DynamicPSF to simply generate the model. Alternatively, you can click the button next to it with the summation icon. This will display the specifications of the average of the selected stars, and is a useful way to quickly check the statistical model that your PSF will represent. The key things I look for in most of my images, which generally have pretty round stars, are a high r (aspect ratio) and a beta (β) that is around 5. You may need to figure out which values represent ideals for your own imaging system, however a high r and a medium β are good things to aim for when trying to optimize your subs.
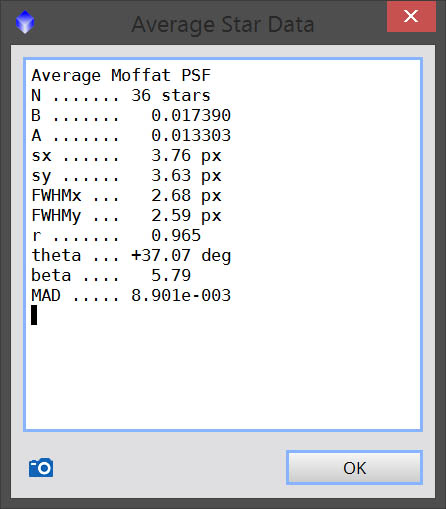
Within the Average Star Data dialog, there is another blue camera icon at the bottom. Once you are done reviewing, if you are happy with the results, click this button to generate the PSF model.
Synthetic PSF
Pending… (Synthetic PSF generation requires a lot of care and will require a fairly extensive round of testing and screenshot generation. Since I recommend DynamicPSF in most cases anyway, this section will have to come later.)
Deconvolution with Regularized Richardson-Lucy
With a solidly well-modeled PSF in hand, we can not get down to the business of actually deconvolving our image. For this, we use the Deconvolution process in PixInsight. This is a non-dynamic process that allows you to configure a PSF (synthetic of two types, or from an external PSF model image), choose and configure a deconvolution algorithm as well as configure countermeasures for potential artifacts, and optionally expand dynamic range of the image to avoid clipping as a result of the deconvolution process. These settings are distributed throughout the five sections of DynamicPSF: PSF, Algorithm, Deringing, Wavelet Regularization and Dynamic Range Extension. Intriguingly, the two least used sections of this tool, Regularization and Dynamic Range expansion, are two of the most important in my opinion. Regularization in particular is one of the key focuses of this article.
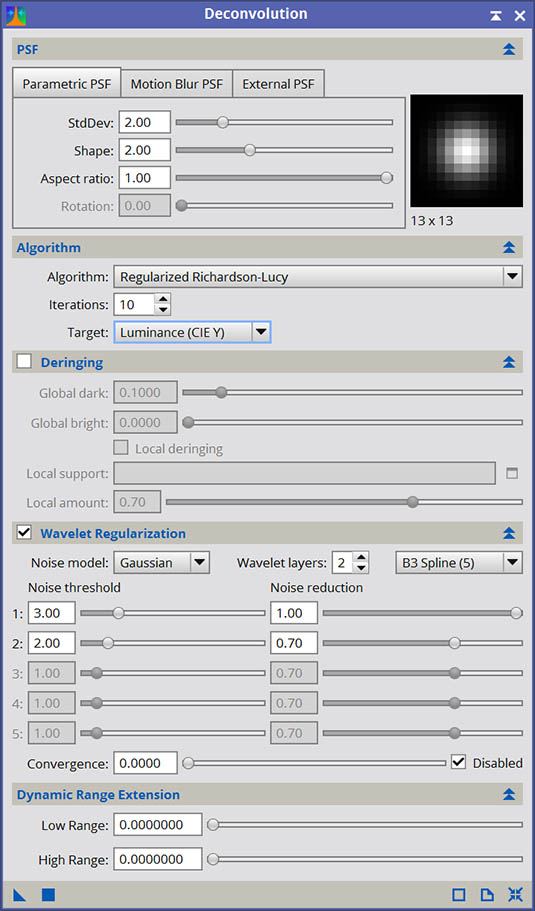
PSF and the Algorithm
First things first, you need to choose your PSF and deconvolution algorithm. For most images, you should be using External PSF, simply choose the image generated by DynamicPSF. If you are creating a synthetic PSF, then you can choose the Parametric PSF tab. Motion blur correction is something that can help, to a degree, with slightly trailed images. That is beyond the scope of this article, however.
For algorithm, you want to choose Regularized Richardson-Lucy. There is another algorithm in there, Van Cittert, as well as the non-regularized versions of each, which will not be covered here. Van Cittert deconvolution is more useful in photometric and spectrophotometry contexts. For image deconvolution, Richardson-Lucy is the proper algorithm, and in most cases, you should be using the regularized version.
To start, you want to set Iterations to 10, however as we progress and tune the algorithm we will be pushing this setting higher and higher until limits are reached. For Target, you can choose to deconvolve just the Luminance, or the full RGB/K. It is actually possible to deconvolve color images, however it requires an extra step that is not particularly obvious in order to avoid the rogue multi-channel artifacts that usually occur when deconvolving color images. Before you actually deconvolve, you must first neutralize the channel weightings for each color channel in the image. This is done with the RGBWorkingSpaces process in PixInsight, simply by setting the Luminance Coefficients to 1.0 for each channel and applying to the image being deconvolved.
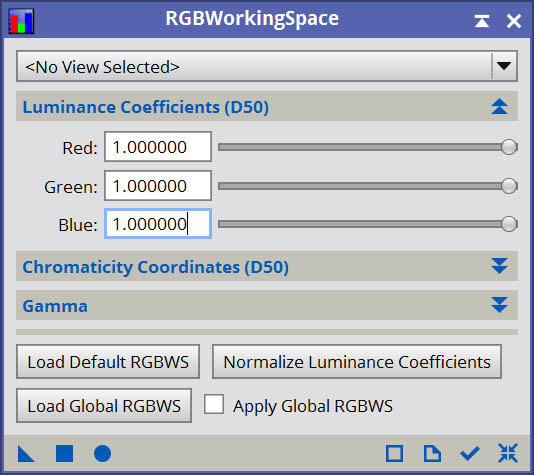
Without this normalization of channel weights, deconvolution will handle each channel differently, resulting in at the very least some mismatches between channels, and at worst, significant psychedelic artifacting. So don’t forget this important step if you need to deconvolve a color image! Note that not every color image can be properly deconvolved. Well-behaved data is still important. In many cases, color images may have “invisible hard edges” in stars or other details that can act as loci for deconvolution artifacts. I have found this to be more common with DSLR data than mono/LRGB. Even with normalization of channel weights, some color images may simply not be deconvolvable in color. The simplest solution there is to extract a luminance or lightness channel and deconvolve that, then recombine with the RGB.
Dealing with Artifacts
Speaking of artifacts, that is the next challenge we need to tackle. Even with proper protection of the algorithm from the noise with regularization, deconvolution is a highly iterative process, and the mechanism by which it operates can create scenarios where it begins to work against itself. At an abstract level, deconvolution is a process of re-concentrating energy that was dispersed by the atmosphere and optical system. It is therefor pulling energy from some locations, and putting that energy back into other locations. In particular, this occurs in the halo areas around stars, and the outer regions of stronger details.
Sometimes, due to the placement of stars and other details, energy might potentially be redistributed improperly, or too much energy may be pulled from locations that simply don’t have enough. This results in “ringing” artifacts, particularly dark ringing, but given enough iterations without correction, what actually occurs is an oscillation as data is moved both into the star as well as to the now brighter outer edge of the dark ring, creating a bright ring. Once a single bright ring exists, another dark ring can form around it, and another bright ring around it, etc. etc. until you have what quite literally looks like an airy pattern:

Thankfully the Deconvolution process has built in mechanisms that help us prevent such artifacts from forming. Called deringing, this is actually another way of regularizing the deconvolution algorithm. Sometimes simply enabling the Deringing section in the process dialog and fiddling with the Global dark setting is enough. I highly recommend doing just that as a primary means of identifying the proper deringing settings for your image. To speed the trial-and-error process up, I also recommend creating a moderately sized preview (around 1/5 to 1/4 of the image) around a key area of interest and detail in your image, and applying deconvolution to that preview instead of the whole image. The smaller total pixel count will make the algorithm run faster, and with PixInsight previews, you can simply use CTRL+SHIFT+Z to toggle back and forth between the deconvolved image and the original to compare results.
Global Dark Estimation
When figuring out a good estimation for global dark deringing, it’s a good idea to start with the default value of 0.1, and adjust first by +0.1 for each test application, until such time as you start seeing what looks like noisy halos being introduced around the stars. This represents the upper limit for global dark, and not to be without further irony, the deringing designed to prevent deconvolution from working against itself…is now working against itself. 😉 Once you find the upper limit, you want to reverse, and adjust by -0.01 for each test application, until such time as you start seeing the airy pattern emerge again. This is the lower limit for global dark. At least, these are the limits without further assistance, which we’ll get to shortly here.

Once you know your limits, you can fiddle with the global dark setting until you find one that does not introduce any dark ringing at all. This may be a little difficult to identify at first, as by default PI starts with a 0.0 value for global bright, and therefor will not prevent any bright rings from forming. In fact, you may encounter another common artifact of deconvolution while finding the best setting for global dark: worms! Worms or webbing (if you don’t like creepy crawly things, beware of deconvolution! It’s an unhallowed tool…), this artifact is actually bright ringing forming around detail structures in the image, faint stars, and even noise. It’s ok if you initially see worms and webbing while finding a good setting for global dark, we’ll correct it momentarily.

Global Bright Estimation
Once you have found your initial global dark setting, you will want to clean up those worms and webbing artifacts. This simply requires giving Global bright a value other than zero. You can start at 0.1, and see if that eliminates the worms and webbing. It very likely will, as a value of 0.1 is quite high for global bright. You may also notice that it pretty much eliminates the deconvolution entirely, leaving only very slight reductions in some of the bigger stars. You will want to reduce global bright by say 0.01 bit by bit until you start seeing the benefits of deconvolution. Keep reducing the value until you begin to see worms or webbing appear again, then bump it back up by 0.01.
Once you enable global bright, and possibly even before, you may start noticing warnings in the console log as deconvolution iterates over your image. These warnings indicate that the deconvolution algorithm is starting to fail, and could very likely start working against itself again. In fact, if you see these warnings printed for every iteration, then the algorithm is likely not functioning properly. This is usually because global dark is too high, and it will need to be reduced. Sadly, this also tends to increase the amount of dark ringing. Finding a proper balance point here can be difficult.

Local Deringing
Enter another level of artifact avoidance features: Local deringing. This is an additional option in the Deringing section that allows us to add some explicit “localized” support for the stars via a star mask image. With local support added, two things will happen. The increased deringing that occurs as a result of reducing the global dark setting will be (ideally) eliminated, or at least reduced, and sadly the amount of deconvolution applied to the rest of the image will diminish somewhat. The use of a local deringing support image can potentially allow the global dark setting to be reduced even further, however, which would in turn allow stronger deconvolution of the image details. Again, it’s a matter of finding a balance point.
To enable local deringing, you need to create a star mask. The resulting star mask image will not actually be used as a mask, instead you will reference it in the local deringing area of the Deringing section of Deconvolution. Generating the star mask is pretty easy. I use the following settings for most of my images, and tweak as necessary until the star mask does it’s job and properly supports local deringing around the stars. This requires some trial and error, however generally speaking only a few cycles are required to generate an ideal mask.
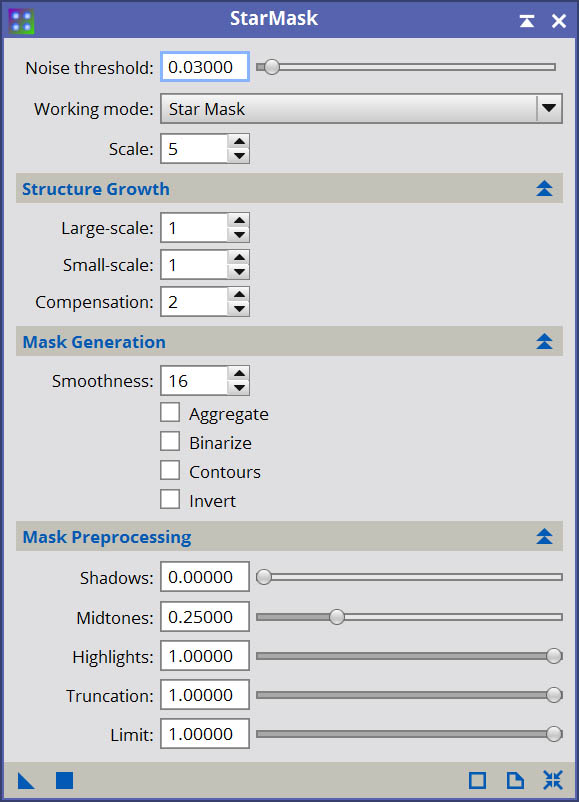
Once you have a star mask, check off the Local deringing option in the Deringing section. Reference your new star mask image in the Local support field, then drop Local amount to 0.2. Apply to your preview and examine the results. You should find that ringing around prominent stars, particularly stars against a mostly bright background but with local dark structure near or underneath them, has dropped. It may not be eliminated completely. You may also find that the enhancement of structural details has lessened somewhat. You should slowly increase Local amount in steps of 0.05 or 0.1, until you find that the level that mostly or entirely eliminates ringing around stars. You may not be able to entirely eliminate ringing around stars against a brighter background with local dark structures, simply due to the nature of deconvolution and it’s redistribution of energy. (I’ll present an alternative solution to such stars next.) You should, however, be able to eliminate ringing around most stars.
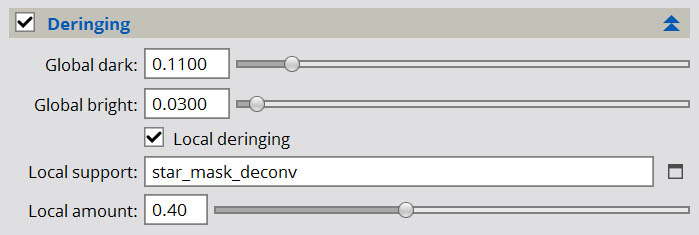
Ultimately, you want to use the LOWEST setting for Local amount that achieves this goal. This may seem counter to other articles that cover deconvolution, however in my experience it is necessary to get the best results. The higher your local amount setting is, the more it will impact the improvement in structural details as well. The default setting of 0.7 is often too high, and I find I am often more around 0.4, maybe even less on some images. You may find that you need higher settings for some images, especially those that have a lot of brighter areas and the potential for more obvious dark ringing (which is not as much of a problem when stars are over dark backgrounds).

Compare this image with final deringing settings to the previous one. Ideally, set one atop the other and quickly swap back and forth to identify the corrected dark rings in the final image.
Configuring Regularization
Once you find the proper settings for deringing, it’s time to go about dealing with the noise. You may also actually find that you need to tweak regularization settings alongside tweaking the deringing settings, as the wavelet regularization actually goes hand in hand with ringing, and is also the primary cause of the warnings you may see when adjusting the deringing settings. If you need to iterate back and forth between adjusting regularization and adjusting deringing that is not unusual. Getting deconvolution configured optimally for each image is just a process that takes some time and dedication! 😉
First off, a quick note about regularization. Unlike masking, which is intended to protect the image data, particularly the background sky noise, from the deconvolution algorithm, it is best to think about regularization as the inverse. Regularization is really more intended to protect the deconvolution algorithm from the noise in the image. I know that may sound odd, however it is the algorithm’s reactions to noise that lead to it’s generation of artifacts. Masking simply attenuates the amount of the deconvolution algorithm’s results that are actually applied to the image. Regularization actually informs the algorithm about the nature of the noise in the image and allows the algorithm to properly deal with it. Ideal regularization settings will allow you to benefit from deconvolution not only from stars, but also in fine details, even somewhat fainter (and usually noisier) details, without either an increase in noise or a change in noise characteristic.
About Wavelet Regularization Settings
The available settings in the Wavelet Regularization section cover modeling the noise, choosing the number of wavelet layers and how the wavelets are scaled, and configuring each wavelet layer. First off is the Noise Model, which can be either Gaussian or Poisson. This defaults to Gaussian, and that is fine for most things, however it may not effectively model the noise for more shallowly exposed data (i.e. narrow band, especially with shorter subs and modern CMOS cameras like the ASI1600 or QHY163). If you are deconvolving data from more lightly exposed subs, Poisson might be a better choice and should better model the noise.
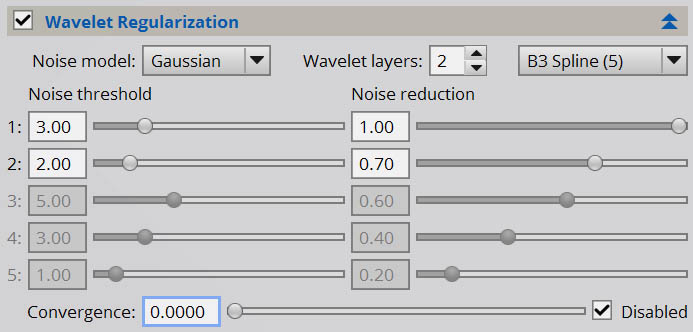
Wavelet Layers is the next option, and this simply lets you choose how many layers of data you are trying to protect. You can choose between one and five layers. Each layer is double the scale of the prior, so layer one is one pixel in scale, layer two is two pixels in scale, layer three is four pixels, layer four is eight pixels layer five is 16 pixels. Most images should only need a few layers of protection, however sometimes you may find that you need to protect more layers. I find I often need 3, maybe even 4 layers, to really avoid any issues with noise. In a couple of cases, I went up to a full five layers, however I suspect there could have been other things I’d done earlier on during pre-processing to clean the data up more, reject bad pixels and average out patterns, etc.
Next to wavelet layers is a dropdown with three scaling options: B3 Spline (5), Linear (3) and Small Scale (3). This is a scaling function for the wavelets themselves. B3 Spline is a bit softer, Linear is a bit sharper. The latter can help you control sharper fine scale noise better. I am honestly not sure what Small Scale actually does, and I generally use B3 Spline for most data anyway.
Next you will find a series of sliders, split into two halves: Noise threshold and Noise reduction. Noise threshold is intended to model the dispersion of noise in the given layer, and is measured in units of sigma. These sound like scary terms, however they have to do with populations within a normal distribution (i.e. Gaussian distribution). You don’t necessarily need to know all that much about the underlying statistics here, just understand the following. First, one “sigma”, denoted by the symbol σ, represents one “standard deviation” from the mean (or median) in a normal distribution. One sigma represents 34.1% of the distribution to one side of the median. Two sigma represent an additional 13.6% of the distribution, also to one side of the median. One sigma on both sides of the median represents 68.2% of the distribution of dispersed (noisy) pixels, while two sigma on both sides of the median represents 95.4% of the distribution of dispersed pixels.
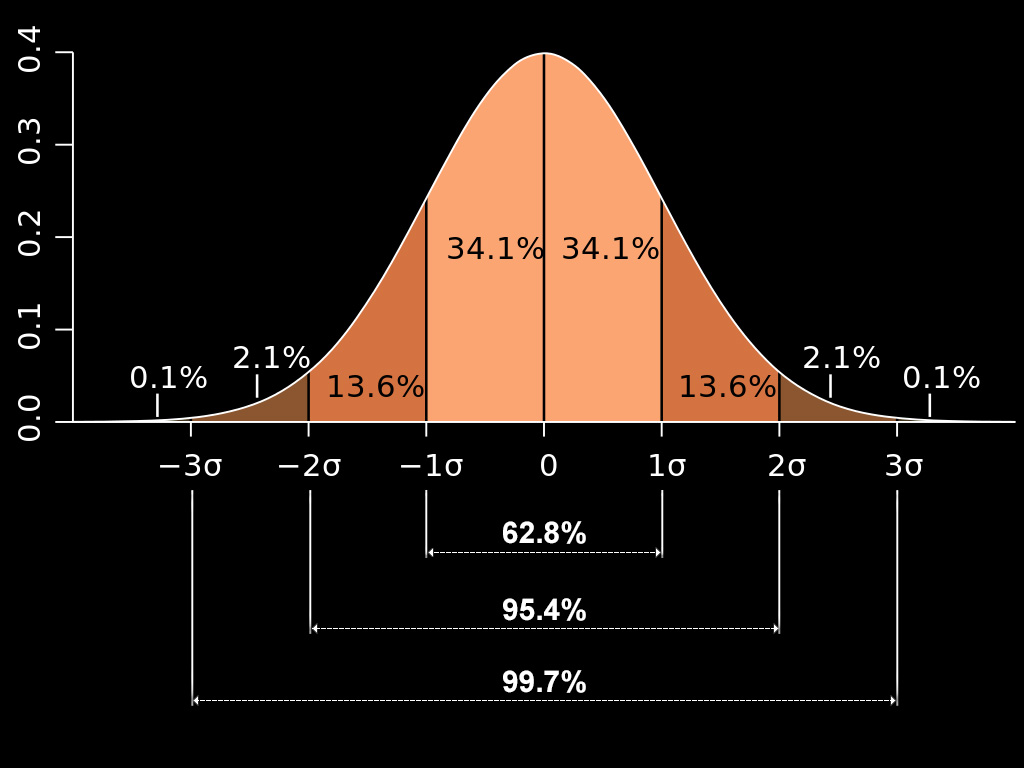
If you think of the image histogram, a hump that grows gradually from the darks, peaks somewhere in the darker medium tones, then gradually falls off towards the lights…you have something that approximates a normal distribution, as pictured above. As you can see, for most images, a sigma of 3 will account for most of the distribution of noisy pixels, covering 99.7% of the total population of pixels. Well, for images that have extremely well behaved noise that follows a Gaussian distribution, anyway.
The Noise reduction setting determines how much the noise of that scale is reduced within the context of the deconvolution algorithm. Note that this will not actually do any noise reduction of your actual image, this reduction is purely for purposes of deconvolving the image. It is a simple percentage, so a value of 0 means no reduction, and a value of 1.0 means complete suppression. For both of these settings, the values are usually scaled through the layers. Layer 1, being the smallest scale, will usually have the highest sigma setting and the highest reduction setting. Layer 2, 3, 4 and 5 will generally be progressively scaled back with smaller sigma and lower reduction.
The final setting is Convergence. Setting is in units of sigma, and defaults to zero, which effectively means to disable convergence. This setting is intended to prevent too many iterations from being performed by setting a lower limit on the standard deviation of the regularized image. Since regularization is suppressing noise, the standard deviation of the data within the deconvolution algorithm will progressively shrink iteration by iteration. By setting a value greater than zero, you can limit the number of iterations if the standard deviation of the image drops below the set value, assuming the maximum iterations configured have not yet been reached. For most images, I simply leave this at the default of zero, disabled.
Initial Regularization Settings
By default, PixInsight’s Deconvolution process actually has two layers of wavelet regularization enabled. These two layers are usually configured with low to moderate protection, and are usually only somewhat effective. This means that the deconvolution algorithm will usually introduce some amount of artifacting within the noise. This may simply look like an increase in the noise amplitude, but usually there is more to it than that. There is also an accompanying change in noise characteristic, it will move away from a simple Poisson or Gaussian profile into something more complex, and often more difficult to reduce with noise reduction tools.
Final Tweaks
Apply and Deconvolve
